
Relatable Explanations for AI Applications
Opportunity
In an increasingly digitised world, data has become more accessible than ever. With this greater availability, learning-based artificial intelligence (AI) has made great strides across fields like computer vision, natural language processing and speech processing. However, such capabilities can be complex—limiting their real-world applications. By making these technologies easier to explain and understand, they can be more widely deployed.
Specifically, the field of audio prediction requires explanations that are more relatable and familiar to users. Currently, explanation techniques for audio present saliency maps on audiograms or spectrograms that are technical and may be difficult for lay-users to understand.
As audio applications become more common in smart homes and healthcare institutions, there is a growing need for such AI models and their predictions to be relatable to examples that users can understand. To truly secure trust from users, the AI models must also mimic how humans think and draw inspiration from human decision-making. As such, new systems must be easy to relate to, explain and understand.
Technology
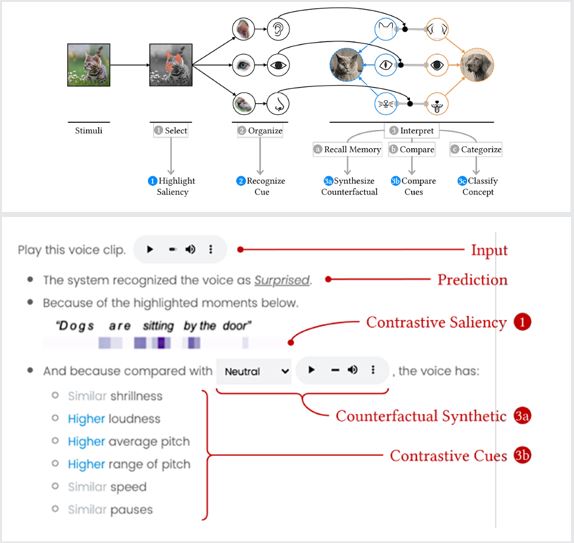
RexNet, or relatable explanation network, is a modular multi-task deep learning model with modules for multiple explanation types. The technology improves prediction performance and reasonable explanations for audio-based prediction models and can potentially be applied to image-based or other AI-based perception predictions. Designed for vocal emotion recognition, RexNet can be implemented in smart homes and mental health settings to identify stress, user engagement and more.
To develop RexNet, the team studied human cognition to understand why and how people relate concepts, information and data. They then designed relatable explanations for AI capabilities based on how humans select, organise and interpret information. On top of offering better prediction and explanations, RexNet also provides more diverse explanations with multiple techniques:
1.Given a voice input, it generates counterfactual voices with different emotions for the user to directly compare.
2.It highlights which parts of the voice are salient for emotion recognition. This is visualised in an easy-to-understand heatmap.
3.It characterises relevant cues (such as modal pitch, pitch variation, volume) and contrasts the differences between the input and counterfactual voices. It can indicate which tasks are more important for the decision, like identifying an angry voice at a lower volume than a happy voice.
4.It predicts the vocal emotion of the input voice.
RexNet can accurately predict emotion and provide relatable explanations that are meaningful and helpful to justify its prediction.
The technology’s framework can be further developed to be used in other audio and visual prediction applications like identifying engine failure, heart disease or even growth patterns that indicate cancer.
The RexNet uer interface is clear and easy to use.

Download
